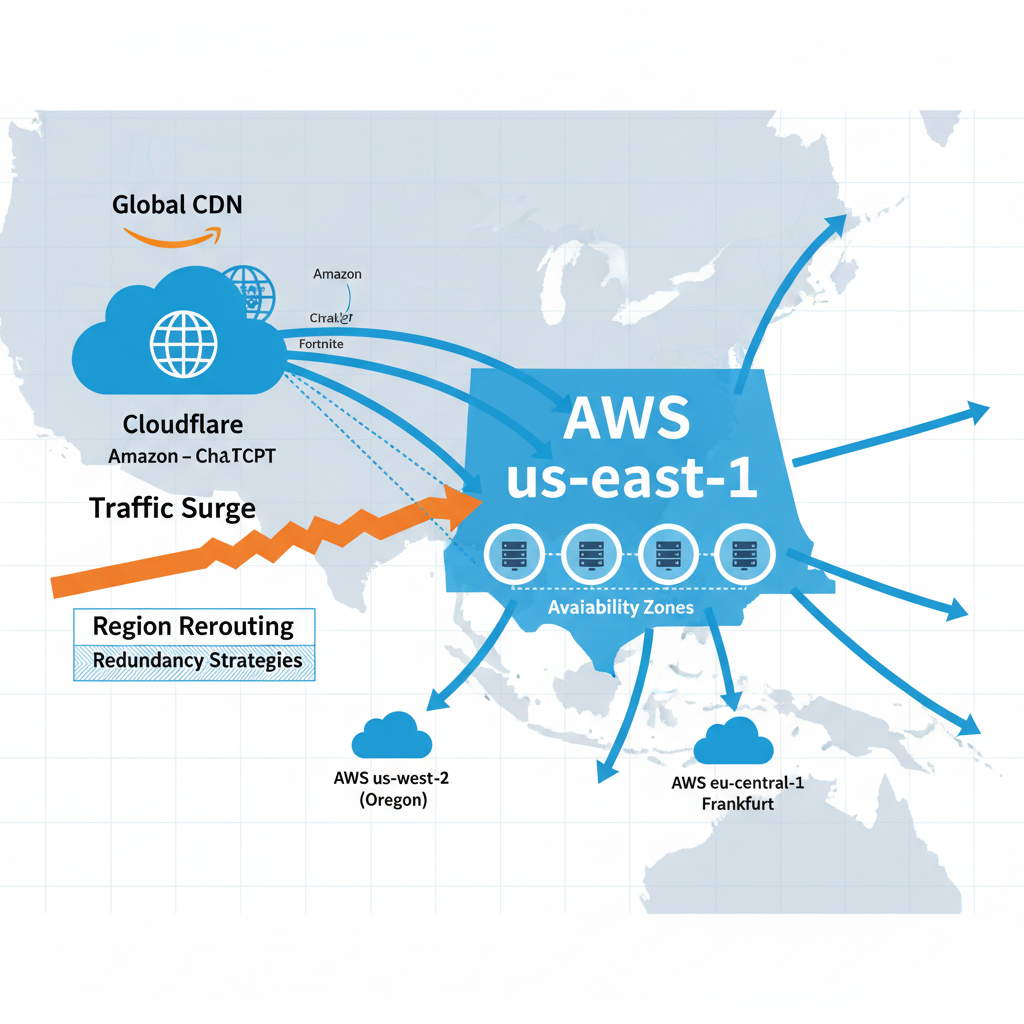
Årsaker og konsekvenser av AWS us-east-1 nedetid i oktober 2025
I oktober 2025 opplevde AWS sin us-east-1-region omfattende nedetid på grunn av en kraftig trafikkøkning mellom Cloudflare og AWS, som førte til overbelastning og nettverksproblemer. Dette resulterte i tjenestebrudd for store tjenester som Amazon, ChatGPT og Fortnite. Selv med infrastrukturen delt inn i flere Availability Zones for redundans, viste hendelsen hvordan regionale feil kan få vidtrekkende konsekvenser. For å redusere sårbarhet brukes strategier som omdirigering av trafikk til andre regioner, bruk av Content Delivery Networks og replikering over flere datasentre. Erfaringene understreker behovet for kontinuerlig forbedring og diversifisering av skyinfrastruktur for å sikre robusthet ved fremtidige trafikkbelastninger og feil.
Summary
Årsaker og konsekvenser av AWS us-east-1 nedetid i oktober 2025
I oktober 2025 opplevde Amazon Web Services (AWS) betydelige problemer i sin us-east-1-region, som dekker Nord-Virginia. Denne hendelsen førte til omfattende feilrater og tjenestebrudd for en rekke store internettjenester, inkludert blant annet Amazon selv, ChatGPT og Fortnite. Nedetiden berørte både tjenester levert direkte gjennom AWS og skytjenester som Vercel, som benytter AWS som underliggende infrastruktur.
AWS sin regionale infrastruktur og redundans
AWS er organisert i flere geografisk adskilte regioner, der us-east-1 er en av de mest sentrale og høyvolumsregionene for mange globale tjenester. Hver region består av flere Availability Zones (AZ) — isolerte datasentre som gir høy tilgjengelighet og redundans ved at arbeidsbelastninger kan flyttes mellom soner ved feil. Likevel kan problemer på regionsnivå, som ved us-east-1, føre til vidtgående konsekvenser fordi mange tjenester har avhengigheter til denne spesifikke regionen, spesielt for lagring og beregning.
Trafikktopp og overbelastning som utløsende faktor
Den primære årsaken til nedetiden i us-east-1 var en kraftig trafikkøkning – et trafikktopp eller trafikkstøt – mellom Cloudflare, et globalt Content Delivery Network (CDN), og AWS. Denne økningen i trafikklaasning skapte betydelig overbelastning på nettverkstilkoblingene til AWS sin infrastruktur i denne regionen. Resultatet var høy latenstid, pakktap og alvorlige feil i kommunikasjonen mellom Cloudflare og AWS us-east-1. Disse nettverksproblemene spredte seg i sin tur til mange applikasjoner og nettsteder som håndterer trafikk via denne infrastrukturen.
Tiltak for å redusere sårbarhet ved regionale feil
For å motvirke konsekvensene av slike regionale feil, har tjenesteleverandører implementert flere strategier:
- Region rerouting: Trafikk kan omdirigeres til andre AWS-regioner eller Availability Zones dersom en region opplever betydelige problemer, for å sikre tjenestetilgjengelighet.
- Bruk av Content Delivery Networks (CDN): CDN som Cloudflare distribuerer innhold globalt, noe som hjelper til med å redusere belastningen på enkeltregioner og forbedrer responstidene for sluttbrukere.
- Redundant infrastruktur og replikering: Skytjenester og databaser som AWS DynamoDB støtter replikering over flere regioner og AZ-er, noe som øker tilgjengeligheten ved feil i én del av infrastrukturen.
Selv om fysiske årsaker som naturhendelser og nettverksfeil kan utløse regionale problemer, var denne hendelsen primært forårsaket av en trafikkøkning fra én enkelt kunde som skapte overbelastning i AWS us-east-1.
Global påvirkning og refleksjoner
Problemene i AWS us-east-1-regionen synliggjør hvordan regionale feil kan forplante seg gjennom store deler av Internett og påvirke både store tjenester og innovative applikasjoner som ChatGPT og Fortnite. Mange tjenester er i dag avhengige av sentrale datasentre som denne, noe som skaper en potensiell sårbarhet til tross for avansert infrastruktur.
Bruken av utviklede strategier som region rerouting, CDN og distribuert replikering er avgjørende, men ikke fullstendig immune mot regionale trafikkbelastninger og feil. Erfaringene fra oktober 2025 understreker behovet for kontinuerlig forbedring og diversifisering av skyinfrastruktur for å oppnå robusthet ved store trafikkhendelser og infrastrukturproblemer.
---
AWS us-east-1-regionens nedetid i oktober 2025 illustrerer tydelig hvordan trafikkbelastning, infrastrukturens regionale oppbygning, og redundansmekanismer spiller en kritisk rolle for tjenestens stabilitet. Til tross for avansert arkitektur kan enkelte hendelser ha vidtrekkende konsekvenser for internettsider, applikasjoner og skytjenester globalt, noe som understreker viktigheten av gode strategier for risikohåndtering i skyen.

Spørsmål og Svar
Spørsmål: Hva skjer med Vercel og AWS nedetid
Svar: Vercel og AWS kan oppleve nedetid på grunn av tekniske feil, nettverksproblemer eller oppdateringer som påvirker tjenestene deres. Slike hendelser kan føre til at nettsider eller applikasjoner som kjører på disse plattformene blir utilgjengelige midlertidig. Begge aktørene jobber kontinuerlig med overvåking og rask feilretting for å minimere nedetid og sikre stabil drift for brukerne sine.
Spørsmål: Hvilke tjenester er påvirket av AWS us-east-1 feil
Svar: Når AWS-regionen us-east-1 opplever feil eller driftsproblemer, kan et bredt spekter av tjenester bli påvirket, inkludert Amazon EC2 (virtuelle servere), S3 (lagring av objekter), RDS (databasehåndtering), Lambda (serverløs databehandling), og DynamoDB (NoSQL-database). Regionens feil kan også påvirke tjenester som bruker us-east-1 som sin primære eller sekundære lokasjon, noe som kan føre til nedetid eller redusert ytelse for applikasjoner som er avhengige av disse tjenestene. AWS jobber kontinuerlig med å minimere slike påvirkninger og gjenopprette normal drift så raskt som mulig.
Spørsmål: Hvordan påvirker AWS og Vercel nedetid internettjenester
Svar: AWS og Vercel er leverandører av skyinfrastruktur og plattformer for hosting av internettjenester. Når det oppstår nedetid hos disse tjenestene, kan det føre til at nettsider og applikasjoner som er hostet hos dem blir utilgjengelige for brukere. Dette påvirker tilgjengeligheten, ytelsen og påliteligheten til internettjenester, noe som kan medføre tap av trafikk, brukeropplevelse og inntekter for bedrifter. Nedetid hos store leverandører kan også få omfattende konsekvenser fordi mange tjenester er avhengige av deres infrastruktur.
Spørsmål: Status på AWS DynamoDB us-east-1 problem
Svar: For å sjekke statusen på AWS DynamoDB i us-east-1-regionen, anbefales det å besøke AWS Service Health Dashboard. Der kan du finne oppdatert informasjon om eventuelle problemer eller avbrudd som påvirker tjenesten i denne regionen. AWS publiserer også detaljer om pågående hendelser og forventet tid for løsning hvis det er et problem.
Spørsmål: Hvordan løses nedetid hos Vercel og AWS
Svar: Nedetid hos Vercel og AWS løses ved bruk av flere strategier som redundans, automatisk failover og overvåking i sanntid. Begge plattformene har omfattende infrastruktur som sikrer høy tilgjengelighet, og de bruker helsesjekker for å oppdage problemer raskt. Når nedetid oppstår, aktiveres reservekapasiteter eller alternative servere automatisk for å minimere påvirkningen. Videre tilbyr de verktøy for utviklere til å rulle tilbake til tidligere stabile versjoner, noe som bidrar til rask gjenoppretting.
Stikkord
Vercel: Vercel er et selskapsplattform som tilbyr hosting og distribusjon av webapplikasjoner, spesielt for utviklere som bruker JavaScript og React. Vercel optimaliserer rask levering av nettsider og støtter utvikling med fokus på ytelse og skalering.
AWS: Amazon Web Services (AWS) er en ledende leverandør av skybaserte tjenester som tilbyr infrastruktur, lagring og beregning for bedrifter og utviklere. AWS brukes globalt til å drifte applikasjoner, inkludert mange moderne nettside- og skytjenesteløsninger.
kode24: kode24 er et norsk nettmagasin som dekker programmering, webutvikling og teknologi nyheter. Plattformen tilbyr artikler, podkaster og ressurser for utviklere i Norge.
The Verge: The Verge er et amerikansk teknologinettsted som dekker nyheter, anmeldelser og analyser innen teknologi, elektronikk og digitale trender. Nettstedet har stor innflytelse på teknologiinteresserte i hele verden.
Gergely Orosz: Gergely Orosz er en utvikler og teknologiforfatter kjent for innsiktsfulle artikler om programvareutvikling og ingeniørpraksis. Hans arbeid fremmer bedre forståelse av utviklingskultur og teamarbeid i teknologibransjen.
Eksterne artikler
- Vercel down? Current problems and outages
- Due to AWS being down, multiple biggest online games ...
- Vercel Status
Artikler i samme kategori
- Kunstig intelligens i programmering og teknologi: Muligheter, utfordringer og nye verktøy
- Forsvaret satser tungt på norske droner og avansert teknologiutvikling
- PlayStation 6 og neste Xbox-konsoll i 2027 med AMD-teknologi og bærekraft
YouTube Video
Title: AWS went down and took half of internet with it 😆 | aws outage #shorts #aws #outage
URL: https://www.youtube.com/shorts/HUIu9HLar2A
Technology